|
Учебник о регулярных выражениях (EditPad
Pro)
В соответствии с пунктом
7.3.h
Пользовательского соглашения, на Народе
нельзя размещать файлы, превышающие по объему 5 Мб
(при этом многотомный архив считается одним файлом)поэтому
эти файлы размещены на depositfiles.com - программа
EditPadPro
|
Исходный текст
Regular
expression tutorial
|
Перевод
Учебник по
регулярным выражениям
(если есть замечания по переводу
сообщите:) |
|
Literal Characters
and Special Characters |
Буквенные
символы и Специальные символы |
|
Literal Characters
The most basic regular expression
consists of a single literal character, e.g.: "a".
It will match the first occurrence of that character in the string.
If the string is "Jack
is a boy", it will match the
"a"
after the "J".
The fact that this "a"
is in the middle of the word does not matter to the regex engine.
If it matters to you, you will need to tell that to the regex engine
by using
word boundaries.
We will get to that later.
This regex can match the second "a"
too. It will only do so when you tell the regex engine to
start searching through the string after the first match. In a
text editor, you can do so by using its "Find Next" or "Search
Forward" function. In a programming language, there is usually
a separate function that you can call to continue searching through
the string after the previous match.
Similarly, the regex "cat"
will match "cat"
in "About cats
and dogs". This regular
expression consists of a series of three literal characters.
This is like saying to the regex engine: find a "c",
immediately followed by an "a",
immediately followed by a "t".
Note that regex engines are case
sensitive by default. "cat"
does not match "Cat",
unless you tell the regex engine to ignore differences in case.
|
Буквенные символы
Самые основные составляющие
регулярного выражения одного символа буквы, т.е. "а".
Это будет соответствовать первому символу буквенного знака в
строке. Если строка "Джек это
мальчик" это будет соответствовать "а"
после "м". Тот факт что
символ "а" находится посредине слова не имеет значения для
регулярных выражений (regex -
сокращение от regular expression). Если
это для Вас имеет значение Вам нужно будет в регулярных
выражениях использовать обозначения границы слова. Мы
доберемся до этого позже.
Это регулярное выражение также
будет соответствовать второй символу буквы "а".
Оно начнет искать как только вы запустите поиск регулярное
выражение после нахождения первого символа. Вы можете это
сделать в текстовом редакторе используя функцию "Find Next"
(Искать следующее) или "Search Forward" (Поиск вперед). В
языках программирования, обычно есть отдельная функция,
которую вы можете использовать для поиска в строке
следующего значения, после нахождения предыдущего.
Вот потому слово "кот"
будет соответствовать "кот"
в предложении "О котах и собаках".
Это регулярное выражение состоит из последовательности из
трех буквенных символов. Это подобно высказыванию
регулярному выражению: найти символ "к",
за которым непосредственно должен быть символ "о",
за которым непосредственно должен быть символ "т".
Предупреждаем что регулярные
выражения по умолчанию чувствительны к регистру (т.е. знак
символа большой буквы и малой буквы - это разные символы).
Выражение "кот" не
соответствует "Кот" если
вы перед тем вы не указали в регулярном выражении
игнорировать различие в регистре.
|
|
Special Characters
Because we want to do more than simply
search for literal pieces of text, we need to reserve certain
characters for special use. In the
regex flavors discussed in this tutorial,
there are 11 characters with special meanings: the opening
square bracket "[",
the backslash "\",
the caret "^",
the dollar sign "$",
the period or dot ".",the
vertical bar or pipe symbol "|",
the question mark "?",
the asterisk or star "*",
the plus sign "+",
the opening round bracket "("
and the closing round bracket ")".These
special characters are often called "metacharacters".
If you want to use any of these
characters as a literal in a regex, you need to escape them with a
backslash. If you want to match "1+1=2",
the correct regex is "1\+1=2".
Otherwise, the plus sign will have a special meaning.
Note that "1+1=2",
with the backslash omitted, is a valid regex. So you will not
get an error message. But it will not match "1+1=2".
It would match "111=2"
in "123+111=234",
due to the special meaning of
the plus character.
If you forget to escape a special
character where its use is not allowed, such as in "+1",
then you will get an error message.
All other characters should not be
escaped with a backslash. That is because the backslash is
also a special character. The backslash in combination with a
literal character can create a regex token with a special meaning.
E.g. "\d"
will match a single digit from 0 to 9. |
Специальные символы
Поскольку мы хотим сделать
больше чем просто поиск отдельных кусков текста мы должны
зарезервировать определенные знаки для специального
использования. В разделе расположенной в этом учебнике есть
11 знаков со специальным значением: открывающиеся квадратные
скобки "[",
обратный слэш (косая обратная черта) "\",
символ "^",
знак доллара "$",
период или точка ".",
вертикальная черта или символ трубы "|",
знак вопроса "$",
звездочка "*",
знак плюса "+",
открывающаяся круглая скобка "("
и закрывающаяся круглая скобка ")".
Эти специальные символы еще часто называют "метасимволы".
Если вы хотите использовать
любой из этих знаков как символы в регулярном выражении, вы
должны впереди их установить обратный слеш. Если вы хотите
найти выражение соответствующее "1+1=2"
правильное регулярное выражение будет иметь вид "1\+1=2".
Иначе знак плюс будет иметь специальное значение.
Заметим что "1+1=2"
без обратного слеша - правильное регулярное выражение.
Поэтому мы не получим сообщение о ошибке. Но это не будет
соответствовать искомому выражению"1+1=2".
Это будет соответствовать "111=2"
в "123+111=234",
благодаря использованию "+"
как специального знака.
Если вы забудете указать
игнорирование специального символа там где его использование
не разрешено, как например в "+1",
тогда вы получите сообщение о ошибке.
Все другие знаки не должны
использоваться со знаком обратный слэш. Потому что обратный
слэш это тоже специальный символ. Обратный слэш в комбинации
с буквенным знаком может создать регулярное выражение со
специальным значением. Например выражение "\d"
будет соответствовать одной цифре от 0 до 9 |
|
Special Characters and
Programming Languages
If you are a programmer, you may be
surprised that characters like the single quote and double quote
are not special characters. That is correct. When using
a regular expression or grep tool like PowerGREP or the search
function of a text editor like EditPad Pro, you should not escape or
repeat the quote characters like you do in a programming language.
In your source code, you have to keep in
mind which characters get special treatment inside strings by your
programming language. That is because those characters will be
processed by the compiler, before the regex library sees the string.
So the regex "1\+1=2"
must be written as "1\\+1=2" in C++ code. The C++ compiler
will turn the escaped backslash in the source code into a single
backslash in the string that is passed on to the regex library.
To match "c:\temp",
you need to use the regex "c:\\temp".
As a string in C++ source code, this regex becomes "c:\\\\temp".
Four backslashes to match a single one indeed.
See the tools and languages section
of this help file for more information on how to use regular
expressions in various programming languages. |
Специальные символы и
языки программирования
Если вы программист, вы возможно
удивлены, что знаки подобно единичной кавычке (апостроф) и
двойной кавычке (знак цитаты) - не специальные символы. Это
верно. Используя регулярное выражение или
grep
инструмент подобно PowerGREP или функцию поиска
текстового редактора подобно вы не должны избегать или
повторять знак двойных кавычек в языках программирования.
В вашем исходном коде вам
придется учитывать какие имеются знаки для специального
исправления в вашем языке программирования. Это для того что
знаки будут обработаны компилятором, перед просмотром строки
библиотекой регулярных выражений. Так что регулярное
выражение "1\+1=2"
должно быть написано как "1\\+1=2" в коде языка
программирования С++. Компилятор С++ преобразует двойной
обратный слэш в исходном коде в единичный обратный слэш в
строке, как это принято в библиотеке регулярных выражений.
Чтобы соответствовать выражению "c:\temp",
вы должны использовать регулярное выражение "c:\\temp".
Как строка в исходном коде языка программирования С++ это
регулярное выражение будет выглядеть "c:\\\\temp".
Четыре обратных слэша, чтобы на самом деле соответствовать
одному.
Прочитайте раздел инструментов и
языков программирования этого файла для получения более
конкретной информации о том, как использовать регулярные
выражения в различных языках программирования. |
|
Non-Printable Characters
You can use special character sequences
to put non-printable characters in your regular expression.
Use"\t"
to match a tab character (ASCII 0x09),"\r"
for carriage return (0x0D)and "\n"
for line feed (0x0A). More exotic non-printables are "\a"
(bell, 0x07), "\e"
(escape, 0x1B), "\f"
(form feed, 0x0C) and "\v"
(vertical tab, 0x0B). Remember that Windows text files use "\r\n"
to terminate lines, while UNIX text files use "\n".
You can include any character in your
regular expression if you know its hexadecimal ASCII or ANSI code
for the character set that you are working with. In the
Latin-1 character set, the copyright symbol is character 0xA9.
So to search for the copyright symbol, you can use "\xA9".
Another way to search for a tab is to use "\x09".
Note that the leading zero is required.
If your regular expression engine
supports
Unicode,
use "\uFFFF"
rather than "\xFF"
to insert a Unicode character. The euro currency sign occupies
code point 0x20A0. If you cannot type it on your keyboard, you
can insert it into a regular expression with "\u20A0".
|
Непечатаемые символы
Вы можете использовать
последовательности специальных символов чтобы поместить
непечатаемые символы в ваше регулярное выражение.
Используйте "\t"
чтобы соответствовать символу таблицы(ASCII 0x09), "\r"
для возврата каретки (0x0D), "\n"
для перевода строки (0x0A). Более экзотические непечатаемые
символы - "\a"
(звуковой сигнал, 0x07), "\e"
(уход, 0x1B), "\f"
(перевод страницы, 0x0C) и "\v"
(вертикальная таблица, 0x0B). Запомните что в текстовых
файлах Windows использует "\r\n",
чтобы закончить линии, в то время как текстовые файлы UNIX
используют "\n".
Вы можете включать в ваше
регулярное выражение любой знак, если вы знаете его
шестнадцатеричный ASCII или ANSI код набора символов с
которыми вы работаете. В латинском наборе символов Latin-1
символ авторского права соответствует коду 0xA9. Поэтому
чтобы найти символ авторского права вы можете использовать
регулярное выражение "\xA9".
Другой пример, чтобы найти таблицу используйте регулярное
выражение "\x09".
Обратите внимание, что нуль вначале не требуется.
Если программа регулярных
выражений поддерживает Unicode, используйте "\uFFFF"
вместо "\xFF",
чтобы вставить знак . Знак валюты евро имеет кодовое
обозначение 0x20A0. Если вы не можете напечатать его на
вашей клавиатуре, вы можете вставить "\u20A0"
в регулярное выражение. |
|
How a Regex Engine
Works Internally |
Как работает
программа
Regex |
|
First Look at
How a Regex Engine Works Internally
Knowing how the regex engine
works will enable you to craft better regexes more easily.
It will help you understand quickly why a particular regex
does not do what you initially expected. This will
save you lots of guesswork and head scratching when you need
to write more complex regexes.
There are two kinds of regular
expression engines: text-directed engines, and
regex-directed engines. Jeffrey Friedl calls them DFA
and NFA engines, respectively. All the
regex flavors treated in this
tutorial are based on
regex-directed engines. This is because certain very
useful features, such as
lazy quantifiers
and
backreferences,
can only be implemented in regex-directed engines. No
surprise that this kind of engine is more popular.
Notable tools that use
text-directed engines are awk, egrep, flex, lex, MySQL and
Procmail. For awk and egrep, there are a few versions
of these tools that use a regex-directed engine.
You can easily find out whether
the regex flavor you intend to use has a text-directed or
regex-directed engine. If backreferences and/or lazy
quantifiers are available, you can be certain the engine is
regex-directed. You can do the test by applying the
regex "regex|regex
not" to the string "regex
not". If the
resulting match is only "regex",
the engine is regex-directed. If the result is "regex
not", then it is
text-directed. The reason behind this is that the
regex-directed engine is "eager".
In this tutorial, after
introducing a new regex token, I will explain step by step
how the regex engine actually processes that token.
This inside look may seem a bit long-winded at certain
times. But understanding how the regex engine works
will enable you to use its full power and help you avoid
common mistakes. |
Первый взгляд
на работу программы
Regex
Знание того, как работает
программа, поможет вам в дальнейшем создавать лучшие и более
простые регулярные выражения. Это поможет вам быстро понять
то, почему специфические регулярные выражения не делают
того, что вы изначально ожидали. Это сохранит вам уйму
времени на обдумывание, когда вам будет нужно написать более
сложные регулярные выражения.
Есть два вида программ
для регулярных выражений: направленные на работу с текстом и
направленные на работу с регулярными выражениями. Джефри
Фриэдл называет их программами соответственно. Все
регулярные выражения рассматриваемые в этом учебнике
основаны на направленные на работу с регулярными
выражениями. Это потому, что определенные очень полезные
особенности, как например ленивые (?) квантификаторы и
обратные (?) справочники могут осуществляться только в
программах направленных на работу с регулярными выражениями.
И в том нет неожиданности, я что этот вид программ более
популярен.
Выдающиеся инструменты, которые
используются в направленных на работу с текстом программах
это awk, egrep, flex, lex, MySQL и Procmail. Для awk и egrep
есть несколько версий этих инструментов которые используют
программы направленные на работу с регулярными выражениями.
Вы можете легко выяснить, какое
направление имеет программа регулярных выражений, которую вы
намереваетесь использовать. Если обратные (?) библиотеки
и/или ленивые (?) квантификаторы доступны, вы можете быть
уверены что программа направлена на работу с регулярными
выражениями. Вы можете провести испытание применяя
регулярное выражение "regex|regex
not" к строке "regex
not". Если будет
только "regex"
эта программа направлена на работу с регулярными
выражениями. если результат будет "regex
not", тогда эта
программа направленная на работу с текстом. Причина этого
состоит в том что программа направлена на работу с
регулярными выражениями "горит желанием"
В этом учебнике после
представления нового знака регулярных выражений я объясню
шаг за шагом как программа регулярных выражений обрабатывает
этот знак. Это часть на первый взгляд может показаться
немногословной в некотором роде. Но понимание работы
программы предоставит вам возможность использовать ее в
полную силу и поможет избежать ошибок. |
|
The
Regex-Directed Engine Always Returns the Leftmost Match
This is a very important point
to understand: a regex-directed engine will always return
the leftmost match, even if a "better" match could be found
later. When applying a regex to a string, the engine
will start at the first character of the string. It
will try all possible permutations of the regular expression
at the first character. Only if all possibilities have
been tried and found to fail, will the engine continue with
the second character in the text. Again, it will try
all possible permutations of the regex, in exactly the same
order. The result is that the regex-directed engine
will return the
leftmost match.
When applying "cat"
to "He
captured a catfish for his cat.",
the engine will try to match the first token in the regex "c"
to the first character in the match "H".
This fails. There are no other possible permutations
of this regex, because it merely consists of a sequence of
literal characters. So the regex engine tries to match
the "c"
with the "e".
This fails too, as does matching the "c"
with the space. Arriving at the 4th character in the
match, "c"
matches "c".
The engine will then try to match the second token "a"
to the 5th character, "a".
This succeeds too. But then, "t"
fails to match "p".
At that point, the engine knows the regex cannot be matched
starting at the 4th character in the match. So it will
continue with the 5th: "a".
Again, "c"
fails to match here and the engine carries on. At the
15th character in the match, "c"
again matches "c".
The engine then proceeds to attempt to match the remainder
of the regex at character 15 and finds that "a"
matches "a"
and "t"
matches "t".
The entire regular expression
could be matched starting at character 15. The engine
is "eager" to report a match. It will therefore report
the first three letters of catfish as a valid match.
The engine never proceeds beyond this point to see if there
are any "better" matches. The first match is
considered good enough.
In this first example of the
engine's internals, our regex engine simply appears to work
like a regular text search routine. A text-directed
engine would have returned the same result too.
However, it is important that you can follow the steps the
engine takes in your mind. In following examples, the
way the engine works will have a profound impact on the
matches it will find. Some of the results may be
surprising. But they are always logical and
predetermined, once you know how the engine works. |
Программа направленная
на поиск регулярных выражений всегда возвращает крайнюю
слева часть
Это очень важный пункт для
понимания: программа направленная на работу с регулярными
выражениями всегда вернет крайнюю слева часть, даже если
"лучшая" часть будет найдена позже. Применять регулярное
выражение к строке программа начнет с первого знака строки.
Она будет пробовать все возможные перестановки регулярного
выражения с первого знака. Только, если все возможные
комбинации не найдены, программа продолжит работу со вторым
знаком по тексту. Снова будет пробовать все возможные
перестановки заказанного регулярного выражения. В результате
программа направленная на работу с регулярными выражениями
вернет крайнюю слева
часть.
Применяя регулярное выражение "кот"
для строки "Он поймал рыбку для
своего кота.", программа будет проверять на
соответствие первому знаку "к"
регулярного выражения первого знака строки "О".
Неверно. В регулярном выражении нет возможности делать
какие-либо перестановки потому что оно состоит из простой
последовательности знаков. Программа тогда будет проверять
на соответствие первому знаку "к"
регулярного выражения второго знака строки "н".
Опять неверно, как и неверно соответствие знаку "к"
пробелу из строки. И только 14 знак строки "к"
совпадет со знаком "к"
регулярного выражения. Тогда программа будет проверять на
соответствие второму знаку регулярного выражения "о"
15 знак строки "у".
Неверно. Тогда программа тогда будет проверять на
соответствие первому знаку "к"
регулярного выражения 15-го знака строки "у".
Опять неверно. И только на 27 знаке строки "к" совпадет с
первым знаком "к". Тогда программа будет проверять на
соответствие второму знаку регулярного выражения "о"
28 знак строки "о".
Опять верно. Тогда программа будет проверять на соответствие
третьему знаку регулярного выражения "т"
29 знак строки "т".
Полное соответствие регулярному
выражению соответствует часть строки начиная с 27 знака.
Программа "горит желанием" сообщить эту часть. Поэтому она
сообщит о первых трех знаках слова "кота" как верную часть.
Программа никогда не пойдет смотреть после этого пункта
оставшуюся часть строки для поиска "лучших" частей. Первая
найденная часть рассматривается как верный ответ.
На этом первом примере работы
программы кажется что программа регулярных выражений
работает подобно поиску обычного текстового редактора.
Программа, направленная на поиск текста, показала бы такой
же результат. Однако важно что в сможете
сопровождать в вашем уме шаг за шагом программы. В
следующих примерах будет показана работа программы на поиске
более сложных частей. Некоторые из результатов возможно
будут удивительны. Но они всегда логичны и предопределены
как вы знаете работой программы |
|
Character Classes or
Character Sets |
Виды символов
или Наборы символов |
|
With a "character class", also called
"character set", you can tell the regex engine to match only one out
of several characters. Simply place the characters you want to
match between square brackets. If you want to match an a
or an e, use "[ae]".
You could use this in "gr[ae]y"
to match either "gray"
or "grey".
Very useful if you do not know whether the document you are
searching through is written in American or British English.
A character class matches only a single
character. "gr[ae]y"
will not match "graay",
"graey"
or any such thing. The order of the characters inside a
character class does not matter. The results are identical.
You can use a hyphen inside a character
class to specify a range of characters. "[0-9]"
matches a single digit between 0 and 9.
You can use more than one range. "[0-9a-fA-F]"
matches a single hexadecimal digit, case insensitively. You
can combine ranges and single characters. "[0-9a-fxA-FX]"
matches a hexadecimal digit or the letter X. Again, the
order of the characters and the ranges does not matter.
|
С "видом символа", также
называемый "набор символа", вы можете указать программе
найти соответствие только одному из нескольких знаков.
Просто разместите знаки, которые вы хотите определить между
квадратными скобками. Если вы хотите найти в тексте символ
а или символ
е вы должны использовать регулярное выражение
[ae].
Вы можете это использовать в выражении "gr[ae]y"
чтобы найти соответствие слову "gray"
(грей) или "grey"
(серый). Очень полезно, если вы не знаете, написан ли
документ, который вы ищите на американском или Британском
английском языке.
Символьные виды соответствуют
только одному символу. "gr[ae]y"
не будет соответствовать "graay",
"graey"
или чему-нибудь подобному. Порядок размещения символов
внутри символьного вида не имеет значения. Результаты будут
идентичны.
Вы можете использовать дефис
внутри символьного вида, чтобы конкретизировать ряд знаков.
"[0-9]"
соответствует одной цифре между цифрами 0
и 9. Вы можете использовать более чем один ряд. "[0-9a-fA-F]"
соответствует одной шестнадцатеричной цифре, чувствительна к
регистру. Вы можете комбинировать ряды и одиночные
символы. соответствует одной шестнадцатеричной цифре или
символу Х. Опять же порядок чередования символов и
рядов не имеет значения. |
|
Useful Applications
Find a word, even if it is misspelled,
such as "sep[ae]r[ae]te"
or "li[cs]en[cs]e".
Find an identifier in a programming
language with "[A-Za-z_][A-Za-z_0-9]*".
Find a C-style hexadecimal number with "0[xX][A-Fa-f0-9]+".
|
Полезные приложения
Поиск слов, даже если это слово с
орфографической ошибкой, как например "sep[ae]r[ae]te"
или
li[cs]en[cs]e".
Поиск идентификатора в языке
программирования с "[A-Za-z_][A-Za-z_0-9]*".
Поиск шестнадцатеричного номера С-стиля
(?) с "0[xX][A-Fa-f0-9]+".
|
|
Negated Character
Classes
Typing a caret after the opening square
bracket will negate the character class. The result is that
the character class will match any character that is not in
the character class. Unlike the
dot,
negated character classes also match (invisible) line break
characters.
It is important to remember that a
negated character class still must match a character. "q[^u]"
does not mean: "a q not followed by a u".
It means: "a
q
followed by a character that is not a u". It will not
match the
q
in the string "Iraq".
It will match the q and the space after the q in "Iraq
is a country". Indeed:
the space will be part of the overall match, because it is the
"character that is not a u" that is matched by the negated character
class in the above regexp. If you want the regex to match the
q, and only the q, in both strings, you need to use
negative lookahead:
"q(?!u)".
But we will get to that later.
|
Отрицательные символьные виды
Символ вознесения в степень после
открывающейся квадратной скобки будет отрицать символьный класс.
Результатом будет что символьный вид будет будет соответствовать
любому знаку, который не находится в символьном виде. В отличие от
точки, негативные символьные виды также находят соответствие
(невидимым) символам окончания линии.
Важно запомнить что отрицательный
символьный вид еще должен соответствовать символам. "q[^u]"
не означает: "за q не следует
u". Это означает: "за
q следует символ, который не
u". Он не будет соответствовать с q
в строку "Iraq"
(Ирак). Это будет соответствовать
q и пробелу после
q в строке "Iraq
is a country" (Ирак является
страной). На самом деле: пробел будет частью общего соответствия,
потому что он является "символом, который не
u", которое соответствует
отрицательному виду символов в приведенном выше регулярном
выражении. Если вы хотите, чтобы регулярные выражения
соответствовали с q, и только q, в двух строках, вам
нужно использовать минус-просмотр вперед:"q(?!u)".
Но мы придем к этому позже. |
|
Metacharacters Inside
Character Classes
Note that the only special characters or
metacharacters inside a character class are the closing bracket (]),
the backslash (\), the caret (^)
and the hyphen (-). The
usual metacharacters
are normal characters inside a character class, and do not need to
be escaped by a backslash. To search for a star or plus, use "[+*]".
Your regex will work fine if you escape the regular metacharacters
inside a character class, but doing so significantly reduces
readability.
To include a backslash as a character
without any special meaning inside a character class, you have to
escape it with another backslash. "[\\x]"
matches a backslash or an x. The closing bracket (]),
the caret (^) and the hyphen (-) can be included by
escaping them with a backslash, or by placing them in a position
where they do not take on their special meaning. I recommend
the latter method, since it improves readability. To include a
caret, place it anywhere except right after the opening bracket.
"[x^]"
matches an x or a caret. You can put the closing bracket right
after the opening bracket, or the negating caret. "[]x]"
matches a closing bracket or an x. "[^]x]"
matches any character that is not a closing bracket or an x.
The hyphen can be included right after the opening bracket, or right
before the closing bracket, or right after the negating caret.
Both "[-x]"
and "[x-]"
match an x or a hyphen.
You can use
non-printable characters
in character classes just like you can use them outside of character
classes. E.g. "[$\u20A0]"
matches a dollar or euro sign, assuming your regex flavor supports
Unicode.
|
Метазнаки внутри видов
символов
Запомните, что единственные специальные
символы или метазнаки внутри видов символов это закрывающаяся
квадратная скобка (]), обратный
слэш (\), знак вознесения в
степень (^) и дефис (-).
Обычные метазнаки это нормальные символы внутри видов символов и они
не должны быть совмещаться с обратным слэшем. Чтобы найти символ
звезды или символ плюс используйте регулярное выражение "[+*]".
Ваше регулярное выражение будет работать отлично, если вы будете
избегать чередования метазнаков внутри видов символов, но делая так
значительно сокращается читабельность.
Чтобы включить в регулярное выражение
обратный слэш как символ, без другого специального означающего
внутривидового символа, вам придется избежать этого с помощью
другого обратного слэша. Регулярное выражение "[\\x]"
соответствует поиску символа обратного слэша или символа
x. Закрывающаяся квадратная скобка
(]), символ вознесения в степень (^) и дефис (-)
могут быть использованы как обычные символы при установке впереди их
обратного слэша, или размещать их в месте где они не будут иметь
значения как специальный символ. Я рекомендую последний метод, так
как это улучшит читабельность. Чтобы включить символ разместите его
где-нибудь но только справа от открывающейся квадратной скобки.
Регулярное выражение "[x^]"
соответствует или символу. Вы можете разместить заключительную
скобку сразу после начальной скобки, или символа отрицания.
Регулярное выражение "[]x]"
означает поиск соответствия символу закрывающейся скобки, или
символу
x. Регулярное выражение
[^]x]означает поиск
соответствия, любого символа, который не является закрывающейся
скобкой или символом . Дефис может включаться сразу после
открывающейся квадратной скобки, или непосредственно перед
закрывающейся квадратной скобкой, или прямо после символа отрицания.
Оба регулярных выражения "[-x]"
и "[x-]"
поиск соответствия символу
x или дефису.
Вы можете использовать непечатаемые
символы у видах символов точно также как вы их можете использовать
за пределами видов символов. Например регулярное выражение "[$\u20A0]"
соответствует поиску соответствия символу доллара или символа евро,
предполагается что ваша разновидность регулярных выражений
поддерживает
Unicode. |
|
Shorthand Character
Classes
Since certain character classes are used
often, a series of shorthand character classes are available.
"\d"
is short for "[0-9]".
"\w"
stands for "word character". Exactly which characters it
matches differs between regex flavors. In all flavors, it will
include "[A-Za-z]".
In most, the underscore and digits are also included. In some
flavors, word characters from other languages may also match.
The best way to find out is to do a couple of tests with the regex
flavor you are using. In the screen shot, you can see the
characters matched by "\w"
in RegexBuddy using various scripts
|
Виды символов стенографии
С тех пор как определенные виды символов
используются часто к ним можно применить символы по принципу
стенографии. Выражение "\d"
есть краткой записью для регулярного выражения "[0-9]".
"\w"
поддерживает "символы слов" (символы букв азбуки).
Точно каким символам это будет соответствовать различно в
зависимости от разновидности регулярного выражения. Во всех
разновидностях это будут включать"[A-Za-z]".
В большинстве случаев также включаются символы подчеркивания и
цифры. В некоторых разновидностях также включаются символы букв
других языков. Лучший способ выяснить - сделать пару испытаний с
разновидностью программы регулярных выражений, которую вы
используете. На скрине экрана вы можете видеть символы которым будет
искать соответствовать выражению "\w"
программа RegexBuddy которая использует различные сценарии. |
|
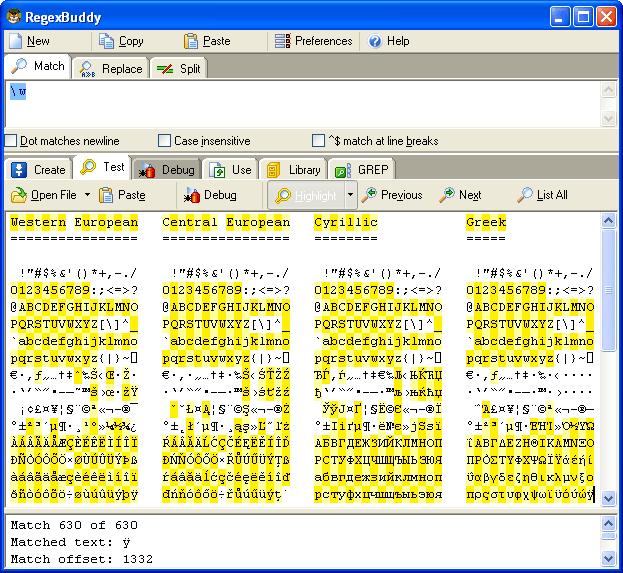 |
|
"\s"
stands for "whitespace character". Again, which characters
this actually includes, depends on the regex flavor. In all
flavors discussed in this tutorial, it includes "[
\t]". That is: "\s"
will match a space or a tab. In most flavors, it also includes
a carriage return or a line feed as in "[
\t\r\n]". Some flavors
include additional, rarely used
non-printable characters
such as vertical tab and form feed.
Shorthand character classes can be used
both inside and outside the square brackets. "\s\d"
matches a whitespace character followed by a digit. "[\s\d]"
matches a single character that is either whitespace or a digit.
When applied to "1
+ 2 = 3", the former regex
will match "
2" (space two), while the
latter matches "1"
(one). "[\da-fA-F]"
matches a hexadecimal digit, and is equivalent to "[0-9a-fA-F]".
|
"\s"
соответствует символу "пробел". Опять же какие символы фактически
входят, зависит от разновидности программы регулярных выражений. Во
всех разновидностях, обсуждаемых в этом учебнике, это включает
"[ \t]".
Это означает что выражение "\s"
будет искать соответствие символу пробела или символу табуляции. В
большинстве разновидностей это будет включать символ возврата
каретки или символ перевод строки как в выражении "[
\t\r\n]". Некоторые
разновидности включают дополнительные, редко используемые
непечатаемые символы, такие как например вертикальная табуляция, или
переход с страницы.
Виды символа стенографии могут
использоваться как внутри, так и снаружи квадратных скобок.
Выражение "\s\d"
соответствует поиску символа пробела стоящего впереди цифры.
Выражение "[\s\d]"
соответствует поиску одного символа, который будет или
пробел, или цифра. Если применить к строке "1
+ 2 = 3" первое
регулярное выражение выдаст "
2" (пробел двойка),
второе выдаст первый подходящий под условие символ - это
будет "1"
(единица). Выражение "[\da-fA-F]"
будет соответствовать шестнадцатеричной цифре и эквивалентно
выражению "[0-9a-fA-F]". |
|
Negated Shorthand
Character Classes
The above three shorthands also have
negated versions. "\D"
is the same as "[^\d]",
"\W"
is short for "[^\w]"
and "\S"
is the equivalent of "[^\s]".
Be careful when using the negated
shorthands inside square brackets. "[\D\S]"
is not the same as "[^\d\s]".
The latter will match any character that is not a digit or
whitespace. So it will match "x",
but not "8".
The former, however, will match any character that is either not a
digit, or is not whitespace. Because a digit is not
whitespace, and whitespace is not a digit, "[\D\S]"
will match any character, digit, whitespace or otherwise.
|
Виды отрицающих символов
стенографии
Рассмотренные выше три вида стенографии
имеют отрицающие версии. Выражение "\D"
такое же как и выражение
[^\d],
выражению "\W"
будет краткой записью для выражения "[^\w]"
и выражение "\S"
является эквивалентом выражения "[^\s]".
Будьте осторожны при использовании
отрицающих видов стенографии внутри квадратных скобок. Выражение "[\D\S]"
не соответствует выражению "[^\d\s]".
Последнее выражение будет соответствовать любому символу, который не
является цифрой или пробелом. Это будет соответствовать
символу буквы "x",
но не символу цифры "8".
Поскольку цифра - не пробел, пробел - не цифра, выражение "[\D\S]"
будет соответствовать любым символам, цифре, пробелу или другим. |
|
Repeating Character
Classes
If you repeat a character class by using
the "?",
"*"
or "+"
operators, you will repeat the entire character class, and not just
the character that it matched. The regex "[0-9]+"
can match "837"
as well as "222".
If you want to repeat the matched
character, rather than the class, you will need to use back
references. "([0-9])\1+"
will match "222"
but not "837".
When applied to the string "833337",
it will match "3333"
in the middle of this string. If you do not want that, you
need to use lookahead and lookbehind.
But I digress. I did not yet
explain how character classes work inside the regex engine.
Let us take a look at that first.
|
Виды повторяющихся символов
Если вид повторяющихся символов
используют операторы "?",
"*"
или "+",
вы будете искать повторения полностью символьного вида, а не
только символ, который ему соответствует. Регулярное
выражение "[0-9]+"
может соответствовать "837"
также как и "222".
Если вы хотите найти
соответствие повторяющемуся символу, вместо символов из
символьного вида, вы должны использовать обратные ссылки.
Выражение "([0-9])\1+"
будет соответствовать "222"
но не "837".
Если применим его к строке "833337",
то в итоге получим цифры "3333"
со средины этой строки. Если вам не надо этого делать, вы
должны использовать предвидение и осмотрительность.
Но я отклонился. Я еще не объяснил, как
символьные виды работают внутри программы регулярных
выражений. Давайте разберемся в этом
сначала. |
|
Looking Inside The
Regex Engine
As I already said: the order of the
characters inside a character class does not matter. "gr[ae]y"
will match "grey"
in "Is his
hair grey or gray?", because
that is the leftmost match. We already saw
how the engine applies a regex
consisting only of literal characters.
Below, I will explain how it applies a regex that has more than one
permutation. That is: "gr[ae]y"
can match both "gray"
and "grey".
Nothing noteworthy happens for the first
twelve characters in the string. The engine will fail to match
"g"
at every step, and continue with the next character in the string.
When the engine arrives at the 13th character, "g"
is matched. The engine will then try to match the remainder of
the regex with the text. The next token in the regex is the
literal "r",
which matches the next character in the text. So the third
token, "[ae]"
is attempted at the next character in the text ("e").
The character class gives the engine two options: match "a"
or match "e".
It will first attempt to match "a",
and fail.
But because we are using a
regex-directed engine, it must continue trying to match all the
other permutations of the regex pattern before deciding that the
regex cannot be matched with the text starting at character 13.
So it will continue with the other option, and find that "e"
matches "e".
The last regex token is "y",
which can be matched with the following character as well. The
engine has found a complete match with the text starting at
character 13. It will return "grey"
as the match result, and look no further. Again, the
leftmost match was returned, even though we put the "a"
first in the character class, and "gray"
could have been matched in the string. But the engine simply
did not get that far, because another equally valid match was found
to the left of it.
|
Взгляд изнутри на
работу программы регулярных выражений
Как я уже сказал: порядок
символов внутри символьного вида не имеет значения.
Выражению "gr[ae]y"
будет найдено соответствие "grey"
в строке "Is
his hair grey or gray?",
потому что это крайнее слева соответствие. Мы
уже рассмотрели как программа применяет регулярные
выражения, состоящие только из буквенных символов. Ниже я
объясню, как работает программа регулярных выражений,
которая выводит более чем одну перестановку. Потому что
выражению "gr[ae]y"
могут соответствовать как "gray"
так и "grey".
Ничего заслуживающего внимания
не случается для первых 12-ти символов в строке. Программа
не может найти соответствие символу "g"
на каждом шагу продолжает искать в следующем символе строки.
Когда программа рассмотрит 13-й символ, будет найдено
соответствие "g".
Программа будет искать соответствие остатку регулярного
выражения с текстом. Следующий по условию необходимый в
регулярном выражении символ "r",
который соответствует следующему символу строки текста.
Третье условие, выражение "[ae]",
сделает попытку найти в тексте следующий символ ("e").
Символьный вид представляет программе два для поиска два
символа: соответствие символу "a",
или соответствие символу "e".
Он попытается найти сначала соответствие "a",
и выдаст ошибку.
Но из-за того, что мы используем
программу ориентированную на регулярные выражения, она
продолжит попытку икать соответствие всем остальным
возможным перестановкам в модели регулярного
выражения до решения что регулярное выражение не может найти
соответствие в тексте 13-му символу. Это будет продолжаться
до тех пор пока символ "e"
регулярного выражения не будет соответствовать символу "e"
строки. Последний необходимый символ "y"
регулярного выражения, которому также может быть найдено
соответствие в следующем символе. Программа найдет полное
соответствие с исходным текстом в 13-м символе. Она вернет "grey"
как результат найденного соответствия и прекратит работу по
поиску других возможных соответствий. Опять же, крайнее
слева соответствие будет возвращено, даже если мы разместим
символ "a"
первым в символьном виде и могло бы найти соответствие "gray"
в строке. Но программа не продолжит работу далее, так как
будет найдено соответствие слева от него.
|
.
|
The Dot
Matches (Almost) Any Character
In regular expressions, the dot
or period is one of the most commonly used
metacharacters.
Unfortunately, it is also the most commonly misused
metacharacter.
The dot matches a single
character, without caring what that character is. The
only exception are newline characters. In all regex
flavors discussed in this tutorial, the dot will not
match a newline character by default. So by default,
the dot is short for the
negated character class
"[^\n]"
(UNIX regex flavors) or "[^\r\n]"
(Windows regex flavors).
This exception exists mostly
because of historic reasons. The first tools that used
regular expressions were line-based. They would read a
file line by line, and apply the regular expression
separately to each line. The effect is that with these
tools, the string could never contain newlines, so the dot
could never match them.
Modern tools and languages can
apply regular expressions to very large strings or even
entire files. All regex flavors discussed here have an
option to make the dot match all characters, including
newlines. In RegexBuddy, EditPad Pro or PowerGREP, you
simply tick the checkbox labeled "dot matches newline".
In Perl, the mode where the dot
also matches newlines is called "single-line mode".
This is a bit unfortunate, because it is easy to mix up this
term with "multi-line mode". Multi-line mode only
affects
anchors,
and single-line mode only affects the dot. You can
activate single-line mode by adding an s after the
regex code, like this:
m/^regex$/s;.
Other languages and regex
libraries have adopted Perl's terminology. When using
the regex classes of the .NET framework, you activate this
mode by specifying
RegexOptions.Singleline,
such as in
Regex.Match("string", "regex",
RegexOptions.Singleline).
In all programming languages and
regex libraries I know, activating single-line mode has no
effect other than making the dot match newlines. So if
you expose this option to your users, please give it a
clearer label like was done in RegexBuddy, EditPad Pro and
PowerGREP.
|
Точка
соответствует (почти) любому символу
В регулярных выражениях точка
или период один из наиболее часто используемых мета
символов. К сожалению, это также более всего
злоупотребляемый мета символ.
Точка соответствует любому
символу не заботясь о том, что это за символ. Единственное
исключение - символы новой строки. Во всех разновидностях
регулярных выражений, рассматриваемых в этом учебнике, точка
по умолчанию не соответствует символу новой строки. Так что
по умолчанию точка есть сокращенной записью отрицающего вида
символов "[^\n]"
(разновидность UNIX регулярных выражений). или
[^\r\n]
(разновидность Windows регулярных выражений).
Это исключение существует по
большей части из-за исторических причин. Первые инструменты,
что использовали регулярные выражения, были основаны на
строке. Они читали файл строку за строкой, и применяли
регулярные выражения отдельно к каждой строке. В итоге в
этих инструментах строка никогда не могла иметь символ новой
строки, так что точка не могла иметь соответствие этим
символам.
Современные инструменты и языки
могут применять регулярные выражения к очень длинным строкам
и даже к целым файлам. Все разновидности регулярных
выражений, обсуждаемых здесь, имеют настройку чтобы точка
соответствовала всем символам, в том числе и символам новой
строки. В программах RegexBuddy, EditPad Pro или PowerGREP,
вы просто выставляете переключатель в положение "точка
соответствует символу новой строки".
В языке программирования Perl
режим, где точка также может соответствовать символу новой
линии назван "режим одиночной линии". Это неудачное название
потому что его легко перепутать с "многострочным режимом".
Многострочный режим воздействует только на якоря (? абзацы,
разделы), а режим одиночной линии воздействует только на
точку. Вы можете активировать режим одиночной линии добавляя
символ s
после кода регулярного выражения, например:
m/^regex$/s;.
Другие языки программирования и
библиотеки регулярных выражений приняли терминологию языка
программирования Perl. Когда вы используете виды регулярных
выражений , вы активируете этот режим при помощи определения
RegexOptions.Singleline,
как например в
Regex.Match("string", "regex",
RegexOptions.Singleline).
Во всех языках программирования
и библиотеках регулярных выражений, которые я знаю,
активация режима одиночной линии не дает никакого эффекта
кроме как создание соответствия точке символу новой линии
(строки). Так что если вы предоставили этот элемент
настройки вашим пользователям, пожалуйста предоставьте
clearer label (?) подобно сделанным в программах RegexBuddy,
EditPad Pro и PowerGREP. |
|
Use The Dot
Sparingly
The dot is a very powerful regex
metacharacter. It allows you to be lazy. Put in
a dot, and everything will match just fine when you test the
regex on valid data. The problem is that the regex
will also match in cases where it should not match. If
you are new to regular expressions, some of these cases may
not be so obvious at first.
I will illustrate this with a
simple example. Let's say we want to match a date in
mm/dd/yy format, but we want to leave the user the choice of
date separators. The quick solution is
"\d\d.\d\d.\d\d".
Seems fine at first. It will match a date like
"02/12/03"
just fine. Trouble is:
"02512703"
is also considered a valid date by this regular expression.
In this match, the first dot matched
"5",
and the second matched
"7".
Obviously not what we intended.
"\d\d[-
/.]\d\d[- /.]\d\d"
is a better solution. This regex allows a dash, space,
dot and forward slash as date separators. Remember
that the dot is not a metacharacter inside a
character class,
so we do not need to escape it with a backslash.
This regex is still far from
perfect. It matches
"99/99/99"
as a valid date.
"[0-1]\d[-
/.][0-3]\d[- /.]\d\d"
is a step ahead, though it will still match
"19/39/99".
How perfect you want your regex to be depends on what you
want to do with it. If you are validating user input,
it has to be perfect. If you are parsing data files
from a known source that generates its files in the same way
every time, our last attempt is probably more than
sufficient to parse the data without errors. You can
find a
better regex to match dates
in the example section.
|
Пользуйтесь точкой
осторожно
Точка - очень мощный мета-символ
регулярных выражений. он позволяет вам лениться. Разместите
точку и все будет соответствовать очень хорошо при проверке
регулярного выражения на действительных данных. Проблема в
том, что регулярное выражение будет соответствовать и в том
случае, где оно не должно было бы соответствовать. если вы
новичок в регулярных выражениях, некоторые из этих случаев
не будут очевидны вначале.
Я покажу это на простом примере.
Например, нам нужно найти соответствие формату даты вида
mm/dd/yy, но мы хотим оставить
пользователю выбор разделителей даты. Быстрое решение - "\d\d.\d\d.\d\d".
Кажется сначала верным. Оно найдет соответствие дате
подобной "02/12/03"
верной. Неверное значение также будет рассматриваться
этим регулярным выражением как дата. При этом первая точка
будет соответствовать "5",
вторая "7".
Очевидно мы этого не хотели.
"\d\d[-
/.]\d\d[- /.]\d\d"
есть лучшим решением. Это регулярное выражение принимает
тире, пробел, наклонную черту и точку как разделитель в
дате. Запомните, что точка внутри символьного вида не
мета-символ, так что перед ней не нужно ставит обратный
слэш.
Это регулярное выражение все еще
далеко от верного решения. Оно найдет "99/99/99"
как соответствие дате. "[0-1]\d[-
/.][0-3]\d[- /.]\d\d"
есть шаг вперед однако еще найдет соответствие "19/39/99".
В совершенстве вы хотите чтобы ваше регулярное выражение
зависело от того, что вы хотите с ним сделать. Если вы
проверяете правильность ввода пользователя, его нужно
сделать совершенным. Если вы анализируете файлы данных
известного исходного текста, что генерируется этими файлами
каждый раз таким же образом, наша последняя попытка имеет
большую вероятность чтобы проанализировать данные без
ошибок. Вы можете найти лучшее регулярное выражение поиска
соответствия дат в разделе примеров. |
|
Use Negated
Character Sets Instead of the Dot
I will explain this in depth
when I present you the repeat operators
star and plus,
but the warning is important enough to mention it here as
well. I will illustrate with an example.
Suppose you want to match a
double-quoted string. Sounds easy. We can have
any number of any character between the double quotes, so
"".*""
seems to do the trick just fine. The dot matches any
character, and the star allows the dot to be repeated any
number of times, including zero. If you test this
regex on
"Put
a "string" between double quotes",
it will match ""string""
just fine. Now go ahead and test it on
"Houston,
we have a problem with "string one" and "string two".
Please respond."
Ouch. The regex matches
""string
one" and "string two"".
Definitely not what we intended. The reason for this
is that the
star
is greedy.
In the date-matching example, we
improved our regex by replacing the dot with a character
class. Here, we will do the same. Our original
definition of a double-quoted string was faulty. We do
not want any number of any character between the
quotes. We want any number of characters that are not
double quotes or newlines between the quotes. So the
proper regex is
""[^"\r\n]*"".
|
Используйте отрицающие символьные
виды вместо точки.
Я объясню это далее, когда я
представлю вам повторно операторы звездочка и плюс, но
предупреждение достаточно важно, чтобы упомянуть его здесь.
Я иллюстрирую
его примером.
Предположим что вы хотите найти
соответствие строке в двойным кавычках. Звучит легко. Мы
можем иметь любое количество символов между двойными
кавычками, такое выражение кажется делает такую попытку
успешной. Точка находит соответствие любым символам, а
звездочка разрешает точке быть повторенной любое количество
раз, в том числе и ноль (то есть ни разу). Если вы проверите
это регулярное выражение на строке "Put
a "string" between double quotes"
("Разместите "строка между двойными кавычкамы"), в
результате найдем верное соответствие . Сейчас идем далее и
проверим его на строке "Houston,
we have a problem with "string one" and "string two".
Please respond."
("Хьюстон, мы имеем проблему с "строка один" и "строка два".
Пожалуйста ответьте.")
Ой. регулярное выражение найдет
соответствие ""string
one" and "string two"".
Определенно мы на это не рассчитывали. Причина этого есть то
что звездочка жадная.
В соответствующем примере для
даты, мы улучшили наше регулярное выражение заменив точку
символьным видом. Здесь мы будем делать то же. Наше
оригинальное определение строки в двойных кавычках было
ошибочно. Мы не хотим никаких чисел и никаких символов
которые не являются двойными кавычками или новой строкой
между кавычками. так что необходимое регулярное выражение
будет ""[^"\r\n]*"".
|
|
Start of
String and End of String Anchors
Thus far, I have explained
literal characters
and
character classes.
In both cases, putting one in a regex will cause the regex
engine to try to match a single character.
Anchors are a different breed.
They do not match any character at all. Instead, they
match a position before, after or between characters.
They can be used to "anchor" the regex match at a certain
position. The caret
"^"
matches the position before the first character in the
string. Applying
"^a"
to "abc"
matches "a".
"^b"
will not match "abc"
at all, because the
"b"
cannot be matched right after the start of the string,
matched by "^".
See below for the inside view of the regex engine.
Similarly,
"$"
matches right after the last character in the string.
"c$"
matches "c"
in "abc",
while "a$"
does not match at all.
|
Поиск в начале
строки и в конце строки
До этих пор я объяснял символы
букв и виды символов. В обоих случаях помещая одно в
регулярное выражение заставит программу регулярных выражений
искать соответствие одному символу.
Якоря другой природы. Они вообще
не соответствуют никакому символу. Вместо этого они ищут
соответствие позиции перед, после или между символами. Они
могут использоваться для того, чтобы регулярное выражение
нашло соответствие определенной позиции. Символ "^"
будет искать соответствие позиции перед первым символом в
строке. Применяя регулярное выражение "^a"
к строке "abc"
найдем соответствие "a".
Выражение "^b"
вообще не может найти соответствие в строке "abc",
потому что "b"
не может соответствовать прямо после начала строки, что
соответствует выражению "^".
Смотрите ниже для представления работы программы регулярных
выражений.
Также знак "$"
соответствует только последнему символу в строке. Выражение
"c$"
находит соответствие символу "c"
для строки "abc",
в то время как выражение "a$"
вообще не находит соответствия. |
|
Useful
Applications
When using regular expressions
in a programming language to validate user input, using
anchors is very important. If you use the code
if ($input =~
m/\d+/)
in a Perl script to see if the user entered an integer
number, it will accept the input even if the user entered
"qsdf4ghjk",
because "\d+"
matches the 4. The correct regex to use is
"^\d+$".
Because "start of string" must be matched before the
match of "\d+",
and "end of string" must be matched right after it,
the entire string must consist of
digits
for "^\d+$"
to be able to match.
It is easy for the user to
accidentally type in a space. When Perl reads from a
line from a text file, the line break will also be stored in
the variable. So before validating input, it is good
practice to trim leading and trailing
whitespace.
"^\s+"
matches leading whitespace and
"\s+$"
matches trailing whitespace. In Perl, you could use
$input =~ s/^\s+|\s+$//g.
Handy use of alternation and /g allows us to do this
in a single line of code. |
Полезные приложения
Когда используете регулярные
выражения в языке программирования для проверки правильности
ввода кода пользователем то использование якорей очень
важно. Если вы используете код if ($input =~
m/\d+/)
в языке программирования Perl, чтобы определить ввел
ли пользователь целое число, будет введено, даже если
пользователь введет "qsdf4ghjk",
потому что выражением "\d+"
будет найдено соответствие числу
4. Правильное регулярное выражение для использования
будет "^\d+$".
Потому что "start of string" (начало строки) должно
быть найдено соответствие перед выражением "\d+"
и "end of string"
(конец строки) должен находиться непосредственно после него,
строка должна полностью состоять из цифр так как она должна
соответствовать выражению "^\d+$".
Это легко для пользователя
случайно нажимающего пробелы. Когда Perl считывает строку
текстового файла, конец строки также будет запомнен в
переменной. Так что перед проверкой достоверности ввода, это
хорошая практика, чтобы упорядочить передвижение и
перемещение пробелов. Выражение "^\s+"
находит соответствие первому пробелу а выражение "\s+$"
находит соответствие последнему пробелу. В Perl вы могли бы
использовать выражение
$input =~ s/^\s+|\s+$//g.
Удобнее использовать чередование а
/g
позволяет нам сделать это в одной строке кода.
|
|
Using
^
and
$
as Start of Line and End of Line Anchors
If you have a string consisting
of multiple lines, like
"first
line\nsecond
line"
(where \n indicates a line break), it is often
desirable to work with lines, rather than the entire string.
Therefore, all the regex engines discussed in this tutorial
have the option to expand the meaning of both anchors.
"^"
can then match at the start of the string (before the
"f"
in the above string), as well as after each line break
(between "\n"
and "s").
Likewise, "$"
will still match at the end of the string (after the last
"e"),
and also before every line break (between
"e"
and "\n").
In text editors like EditPad
Pro
or GNU Emacs, and regex tools like PowerGREP,
the caret and dollar always match at the start and end of
each line. This makes sense because those applications
are designed to work with entire files, rather than short
strings.
In all programming languages and
libraries discussed in this help file, except
Ruby, you have to explicitly activate this extended
functionality. It is traditionally called "multi-line
mode". In
Perl, you do this by adding an m after the regex
code, like this:
m/^regex$/m;.
In .NET, the anchors match before and after newlines
when you specify
RegexOptions. Multiline,
such as in
Regex.Match ("string", "regex", RegexOptions.Multiline). |
Использование
^
и
$
как определение начала строки и конца строки
Если вы имеете текст состоящий
из множества строк, подобно "первая
строка\nвторая
строка" (где
\n означает окончание строки), удобнее работать со
строками вместо одной длинной строки. Поэтому все программы
регулярных выражений, обсуждаемые в этой статье, имеют
элемент настройки, чтобы развернуть значения обеих
якорей(?). Знак "^"
может тогда соответствовать началу строки (перед буквой
"п"
в упомянутой выше строке), также как и после каждого
окончания строки (между "\n"
и "в").
Также знак "$"
будет всегда соответствовать окончанию строки (после
последнего знака "а"),
и также перед каждым окончанием строки (между "а"
и "\n").
В текстовых редакторах,
подобных EditPad Pro или GNU Emacs, и в
инструментах регулярных выражений подобных PowerGREP,
символы вознесение в степень и доллар всегда соответствуют
началу и концу каждой строки. Смысл состоит в том, что эти
приложения позволяют работать с полными файлами вместо
коротких строк.
Во всех языках программирования
и библиотеках что рассматриваются в этой статье, кроме
Ruby, вы должны непосредственно активировать эту
расширенную функциональность. Она традиционно называется
"многострочный режим". В
Perl
вы сделаете это при помощи загрузки после кода
регулярного выражения, подобно этому:
m/^regex$/m;.
В .NET, якоря соответствуют перед и после новой
строки, когда вы конкретизируете
RegexOptions. Multiline, подобна как
Regex.Match ("string", "regex", RegexOptions.Multiline). |
|
Permanent
Start of String and End of String Anchors
"\A"
only ever matches at the start of the string.
Likewise,
"\Z"
only ever matches at the end of the string. These two
tokens never match at line breaks. This is true in all
regex flavors discussed in this tutorial, even when you turn
on "multiline mode". In EditPad Pro and
PowerGREP, where the caret and dollar always match at
the start and end of lines,
"\A"
and "\Z"
only match at the start and the end of the entire file. |
Постоянные обозначения
начала строки и конца строки
Обозначения "\A"
иногда соответствуют началу строки. Также "\Z"
иногда соответствуют концу строки. Эти два обозначения
никогда не соответствуют окончанию строки. Это верно во всех
разновидностях регулярных выражений, что рассматриваются
в этой статье, даже когда вы запускаете "многострочный
режим". В
EditPad Pro и
PowerGREP, где символ вознесения в степень и символ
доллара всегда соответствуют началу и концу строки, "\A"
и "\Z"
только соответствуют началу и концу целого файла.
|
|
Zero-Length
Matches
We saw that the anchors match at
a position, rather than matching a character. This
means that when a regex only consists of one or more
anchors, it can result in a zero-length match.
Depending on the situation, this can be very useful or
undesirable. Using
"^\d*$"
to test if the user entered a number (notice the use of the
star
instead of the
plus),
would cause the script to accept an empty string as a valid
input. See below.
However, matching only a
position can be very useful. In email, for example, it
is common to prepend a "greater than" symbol and a space to
each line of the quoted message. In VB.NET, we
can easily do this with
Dim Quoted as String = Regex.Replace(Original, "^",
"> ", RegexOptions.Multiline).
We are using multi-line mode, so the regex
"^"
matches at the start of the quoted message, and after each
newline. The Regex.Replace method will remove the
regex match from the string, and insert the replacement
string (greater than symbol and a space). Since the
match does not include any characters, nothing is deleted.
However, the match does include a starting position, and the
replacement string is inserted there, just like we want it. |
Соответствие нулевой
длины
Мы увидели что якоря
соответствуют позиции вместо соответствия символу. Это
означает что, когда регулярное выражение содержит один или
более якорей, оно может иметь в результате соответствие
нулевой длины. В зависимости от ситуации это может быть
очень полезно или нежелательным. Использование выражения "^\d*$"
для проверки ввода пользователем номера (обратите внимание
на использование символа звездочки вместо символа плюс),
заставит скрипт принять пустую строку как правильный ввод.
Смотрим ниже.
Однако соответствие такой
позиции может быть очень полезным. Например, в электронной
почте обычно чтобы предварительно рассмотреть символ "больше
чем" и "пробел" каждой строке каждой строке котируемого
сообщения. В VB.NET
мы можем легко это сделать с
Dim Quoted as String = Regex.Replace(Original, "^",
"> ", RegexOptions.Multiline.
Мы используем многострочный режим, поэтому регулярное
выражение соответствует началу котируемого сообщения и
после каждой новой строки. Метод будет удалять
регулярное сообщение со строки и вставит строку замены
(больше чем символ вознесения в степень и пробел). Когда
соответствие не содержит никаких символов, ничего не
удаляется. Однако, когда соответствие содержит начальную
позицию, строка замены будет вставлена там, точно по нашему
желанию. |
|
Strings
Ending with a Line Break
Even though
"\Z"
and "$"
only match at the end of the string (when the option for the
caret and dollar to match at embedded line breaks is off),
there is one exception. If the string ends with a line
break, then "\Z"
and "$"
will match at the position before that line break, rather
than at the very end of the string. This "enhancement"
was introduced by Perl, and is copied by many regex
flavors, including Java, .NET and PCRE.
In Perl, when reading a line from a file, the
resulting string will end with a line break. Reading a
line from a file with the text "joe" results in the
string
"joe\n".
When applied to this string, both
"^[a-z]+$"
and "\A[a-z]+\Z"
will match "joe".
If you only want a match at the
absolute very end of the string, use
"\z"
(lower case z instead of upper case Z).
"\A[a-z]+\z"
does not match "joe\n".
"\z"
matches after the line break, which is not matched by the
character class.
|
Строки,
заканчивающиеся символом окончания строки
Даже если "\Z"
и "$"
соответствуют только окончанию строки (когда настройка для
символа вознесения в степень и доллара для поиска
соответствия во вложенной окончании линии будет выключена)
есть одно исключение. Если строка заканчивается символом
окончания линии, тогда "\Z"
и "$"
будут искать соответствие позиции перед тем символом
окончания строки, вместо самого окончания строки. Это
расширение было введено в языке программирования
Perl и скопировано многими разновидностями регулярных
выражений, в том числе языками программирования
Java, .NET и
PCRE. В
Perl перед чтением строки из файла результирующей
строкой будет будет окончание в символом окончания линии.
Чтение строки из файла с текстом "joe" будет
результат в строке "joe\n".
Когда применим к этой строке оба регулярные выражения "^[a-z]+$"
и "\A[a-z]+\Z"
будет найдено соответствие "joe".
Если вы только хотите найти
соответствие абсолютному окончанию строки, используйте
регулярное выражение "\z"
(нижний регистр
z вместо верхнего регистра
Z). Выражение "\A[a-z]+\z"
не находит соответствия "joe\n".
Выражение "\z"
находит соответствие после окончания строки, которое не
находит соответствие при помощи символьных видов. |
|
Looking
Inside the Regex Engine
Let's see what happens when we
try to match "^4$"
to "749\n486\n4"
(where
\n
represents a newline character) in multi-line mode.
As usual, the regex engine starts at the first character:
"7".
The first token in the regular expression is
"^".
Since this token is a zero-width
token, the engine does not try to match it with the
character, but rather with the position before the character
that the regex engine has reached so far.
"^"
indeed matches the position before
"7".
The engine then advances to the next regex token:
"4".
Since the previous token was
zero-width, the regex engine does not advance to the
next character in the string. It remains at
"7".
"4"
is a literal character, which does not match
"7".
There are no other permutations
of the regex, so the engine starts again with the first
regex token, at the next character:
"4".
This time, "^"
cannot match at the position before the 4. This
position is preceded by a character, and that character is
not a newline.
The engine continues at
"9",
and fails again. The next attempt, at
"\n",
also fails. Again, the position before
"\n"
is preceded by a character,
"9",
and that character is not a newline.
Then, the regex engine arrives
at the second "4"
in the string. The
"^"
can match at the position before the
"4",
because it is preceded by a newline character. Again,
the regex engine advances to the next regex token,
"4",
but does not advance the character position in the string.
"4"
matches "4",
and the engine advances both the regex token and the string
character. Now the engine attempts to match
"$"
at the position before (indeed: before) the
"8".
The dollar cannot match here, because this position is
followed by a character, and that character is not a
newline.
Yet again, the engine must try
to match the first token again. Previously, it was
successfully matched at the second
"4",
so the engine continues at the next character,
"8",
where the caret does not match. Same at the six and
the newline.
Finally, the regex engine tries
to match the first token at the third
"4"
in the string. With success. After that, the
engine successfully matches
"4"
with "4".
The current regex token is advanced to
"$",
and the current character is advanced to the very last
position in the string: the void after the string. No
regex token that needs a character to match can match here.
Not even a
negated character class.
However, we are trying to match a dollar sign, and the
mighty dollar is a strange beast. It is zero-width, so
it will try to match the position before the current
character. It does not matter that this "character" is
the void after the string. In fact, the dollar will
check the current character. It must be either a
newline, or the void after the string, for
"$"
to match the position before the current character.
Since that is the case after the example, the dollar matches
successfully.
Since
"$"
was the last token in the regex, the engine has found a
successful match: the last
"4"
in the string.
|
Посмотрим механизм
регулярных выражений изнутри
Давайте посмотрим, что случится,
когда мы попробуем найти соответствие регулярного выражения
"^4$"
применив его к строке "749\n486\n4"
(где \n
представляет собой обозначение новой строки) в многострочном
режиме.
Как обычно программа регулярных
выражений начинает искать соответствие с символа "7",
первый необходимый символ в регулярном выражении - "^".
Так как эта лексема
широтно-нулевая лексема, программа не найдет верного
соответствия в этом символе, а
скорее с позицией перед символом которую программа
регулярных выражений достигла. Выражение "^"
находит соответствие позиции перед символом "7".
Программа затем переходит к следующей лексеме регулярного
выражения: "4".
Так как предыдущая лексема была
широтно-нулевой, программа регулярных выражений не
продвинется к следующему символу в строке. Она остановится
на "7".
"4"
необходимый символ, который не соответствует "7".
В программе регулярных выражений
нет больше других возможных перестановок тогда программа
начнет работу с первой лексемой регулярного выражения в
следующем символе строки: "4".
Одновременно не может найти соответствие позиции перед
4. Эта позиция не имеющая символа, и этот символ не
новая строка.
Программа продолжает с "9"
и снова не соответствие. следующая попытка с "\n"
также терпит неудачу. Опять позиция перед "\n"
расчищена символом, "9",
и этот символ не новая линия.
Тогда программа регулярных
выражений прибудет ко второму символу "4"
в строке. "^"
может найти соответствие позиции перед "4"
потому что это соответствует обозначению новой строки. Опять
программа регулярных выражений переходит к следующей
лексеме, "4",
но не продвигает символьную позицию в строке. Выражение "4"
находит соответствие "4"
и программа регулярных выражений продвигает как лексему
регулярных выражений так и символ строки. Теперь программа
попытается найти соответствие "$"
на позиции перед (именно: перед) "8".
Доллар не может найти соответствие здесь,
потому что эта позиция оканчивается символом, а этот символ
- не начало строки.
Опять программа должна пробовать
найти соответствие первой лексеме по новой. Ранее было
успешно найдено соответствие второй "4",
так что программа продолжает со следующего символа "8",
где символ вознесения в степень не находит соответствия. То
же происходит на "6" и
символе новой линии "\n".
Наконец программа регулярных
выражений попробует найти соответствие первой лексеме в
третьей "4".
Успешно. После этого программа успешно находит соответствие
"4"
с "4".
Теперь регулярное выражение передвигает лексему к "$",
а поиск текущего символа передвигается к самой последней
позиции в строке: нет ничего после строки. Нет лексемы
регулярного выражения, чтобы можно было здесь найти
соответствие. Даже нет отрицающих символьных видов. Однако
мы попробуем найти соответствие знаку "$",
а могущественный доллар - странный зверь. Так как это
широтно-нулевое, поэтому будет пробовать найти соответствие
позиции перед текущим символом. Не имеет никакого значения
что этот "символ" - пустота после строки. Фактически доллар
проверит текущий символ. Это должна быть или новая линия,
или пустота после строки для "$"
чтобы найти соответствие позиции перед текущим символом. В
этом случае примера доллар успешно находит соответствие.
С того как "$"
стал последней лексемой в регулярном выражении программа
успешно нашла соответствие: последняя "4"
в строке. |
|
Another
Inside Look
Earlier I mentioned that
"^\d*$"
would successfully match an empty string. Let's see
why.
There is only one "character"
position in an empty string: the void after the string.
The first token in the regex is
"^".
It matches the position before the void after the string,
because it is preceded by the void before the string.
The next token is "\d*".
As we will see later, one of the
star's
effects is that it makes the
"\d",
in this case, optional. The engine will try to match
"\d"
with the void after the string. That fails, but the
star turns the failure of the
"\d"
into a zero-width success. The engine will proceed
with the next regex token, without advancing the position in
the string. So the engine arrives at
"$",
and the void after the string. We already saw that
those match. At this point, the entire regex has
matched the empty string, and the engine reports success.
|
Другой взгляд изнутри
Раньше я упоминал, что выражение
"^\d*$"
успешно находит соответствие порожней строке. Давайте
рассмотрим почему.
Есть только одна "символьная
позиция в порожней строке: пустота (нет ничего) в строке.
Первая лексема в регулярном выражении "^".
Она находит соответствие позиции пустоты после строки и
перед порожней строкой, потому что это подготавливает к
пустоте перед строкой. Следующая лексема "\d*".
Как мы рассмотрим позже один их эффектов звездочки то что
делает "\d"
в данном случае необязательным. Программа будет пробовать
искать соответствие "\d"
пустоте после строки. Это неверно, но звезда обратит неудачу
"\d"
в широтно-нулевой успех. Программа приступит к следующей
лексеме регулярного выражения без перехода к следующей
позиции в строке. Так что программа приступает к "$"
и пустоте после строки. Мы уже увидели, что это
соответствует. В этот момент регулярное выражение находит
полное соответствие порожней строке и программа сообщает об
успехе. |
|
Caution for
Programmers
A regular expression such as
"$"
all by itself can indeed match after the string. If
you would query the engine for the character position, it
would return the length of the string if string indices are
zero-based, or the length +1 if string indices are one-based
in your programming language. If you would query the
engine for the length of the match, it would return zero.
What you have to watch out for
is that String[Regex.MatchPosition] may cause an
access violation or segmentation fault, because
MatchPosition can point to the void after the string.
This can also happen with
"^"
and "^$"
if the last character in the string is a newline.
|
Предостережения
программистам
Регулярное выражение как
например "$"
само собой действительно может искать соответствие после
строки. Если бы вы усомнились в программе для позиции
символа, она вернула бы длину строки если строковые индексы
отсчитываются от нуля или длина + 1, если строковые индексы
отсчитываются от 1 в вашем языке программирования. Если вы
сомневаетесь в программе поиска соответствия длины будет
возвращен ноль.
Чего вам надо остерегаться
так это
String[Regex.MatchPosition], что может вызвать отказ
в доступе или некоторый дефект, потому что MatchPosition
может указать на пустоту после строки. Это может также
случиться с "^"
и "^$",
если последний символ в строке новая строка.
|
|
Word
Boundaries
The metacharacter "\b"
is an
anchor
like the caret and the dollar sign. It matches at a
position that is called a "word boundary". This match
is zero-length.
There are four different
positions that qualify as word boundaries:
-
Before the first character in the string, if the first
character is a word character.
-
After the last character in the string, if the last
character is a word character.
-
Between a word character and a non-word character
following right after the word character.
-
Between a non-word character and a word character
following right after the non-word character.
Simply put: "\b"
allows you to perform a "whole words only" search using a
regular expression in the form of "\bword\b".
A "word character" is a character that can be used to form
words. All characters that are not "word characters"
are "non-word characters". The exact list of
characters is different for each regex flavor, but all word
characters are always matched by the
short-hand character class
"\w".
All non-word characters are always matched by "\W".
In Perl and the other
regex flavors discussed in this tutorial, there is only one
metacharacter that matches both before a word and after a
word. This is because any position between characters
can never be both at the start and at the end of a word.
Using only one operator makes things easier for you.
Note that "\w"
usually also matches digits. So "\b4\b"
can be used to match a 4 that is not part of a larger
number. This regex will not match "44
sheets of a4".
So saying ""\b"
matches before and after an alphanumeric sequence" is more
exact than saying "before and after a word".
|
Границы слова
Метасимвол "\b"
это якорь подобный знакам вознесения в степень и доллара. Он
находит соответствие позиции называемой "граница слова". Это
соответствие нулевой длины.
Имеются четыре различных позиции
которые обозначаются как границы слова:
- перед первым символом в
строке, если первый символ это символ слова.
- после последнего символа в
строке, если последний символ это символ слова.
- между символом слова и
символом не слова следующим справа после символа слова.
- между символом не слова и
следующим символом слова справа после символа не слова.
Просто введите: "\b"
разрешает нам выполнять поиск "только целых слов", используя
регулярное выражение вида "\bword\b".
"Символ слова" это символ который может использоваться чтобы
формировать слова. Все символы которые не являются
"символами слова". Точный список символов разный для каждой
разновидности регулярных выражений, но все символы слова
всегда соответствуют краткой записи символьного вида "\w".
Все символы не слова соответствуют "\W".
В языке программирования и
других разновидностях регулярных выражений рассматриваемых в
этой статье есть только один мета символ, который
соответствует позиции как перед словом так и после слова.
Это потому что любая позиция между символами никогда не
может находиться как в начале так ив конце слова.
Использование только одного оператора делает обозначения для
вас попроще.
Отметьте что "\w"
также согласовывает и цифры. Поэтому выражение "\b4\b"
может использоваться для поиска соответствия 4
который не является частью большого числа. Это регулярное
выражение не находит соответствия "44
sheets of a4".
Поэтому говорят ""\b"
находит соответствие до и после буквенно-цифровой
последовательности" точнее надо сказать "до и после слова". |
|
Negated Word
Boundary
"\B"
is the negated version of "\b".
"\B"
matches at every position where "\b"
does not. Effectively, "\B"
matches at any position between two word characters as well
as at any position between two non-word characters.
|
Отрицание границы
слова
Выражение "\B"
это отрицающая версия выражения "\b".
"\B"
находит соответствие каждой позиции где "\b"
не находит. Фактически "\B"
находит соответствие любой позиции между двумя символами
словами также как и любой позиции между двумя символами не
слова. |
|
Looking
Inside the Regex Engine
Let's see what happens when we
apply the regex "\bis\b"
to the string "This
island is beautiful".
The engine starts with the first token "\b"
at the first character "T".
Since this token is zero-length, the position before the
character is inspected. "\b"
matches here, because the T is a word character and
the character before it is the void before the start of the
string. The engine continues with the next token: the
literal "i".
The engine does not advance to the next character in the
string, because the previous regex token was zero-width. "i"
does not match "T",
so the engine retries the first token at the next character
position.
"\b"
cannot match at the position between the "T"
and the "h".
It cannot match between the "h"
and the "i"
either, and neither between the "i"
and the "s".
The next character in the string
is a space. "\b"
matches here because the space is not a word character, and
the preceding character is. Again, the engine
continues with the "i"
which does not match with the space.
Advancing a character and
restarting with the first regex token, "\b"
matches between the space and the second "i"
in the string. Continuing, the regex engine finds that
"i"
matches "i"
and "s"
matches "s".
Now, the engine tries to match the second "\b"
at the position before the "l".
This fails because this position is between two word
characters. The engine reverts to the start of the
regex and advances one character to the "s"
in "island".
Again, the "\b"
fails to match and continues to do so until the second space
is reached. It matches there, but matching the "i"
fails.
But "\b"
matches at the position before the third "i"
in the string. The engine continues, and finds that "i"
matches "i"
and "s"
matches "s".
The last token in the regex, "\b",
also matches at the position before the second space in the
string because the space is not a word character, and the
character before it is.
The engine has successfully
matched the word "is"
in our string, skipping the two earlier occurrences of the
characters i and s. If we had used the
regular expression "is",
it would have matched the "is"
in "This".
|
Посмотрим механизм
регулярных выражений изнутри
Давайте посмотрим, что будет,
если применить регулярное выражение "\bis\b"
к строке "This
island is beautiful".
Программа начнет с первого символа лексемы "\b"
на первом символе "T".
Так как это лексема нулевой строки, позиция перед символом
проверена. "\b"
находит здесь соответствие потому что Т
это символ слова и символ перед ним это пустота перед
началом строки. Программа продолжает работу со следующей
лексемой: буквой "i".
Программа не продвигается к следующему символу в строке
потому что предыдущая лексема регулярного выражения была
нулевой ширины. "i"
не находит соответствия "T",
поэтому программа повторяет первую лексему к следующему
символу позиции.
Выражение "\b"
не может найти соответствие позиции между символами "T"
и "h".
Оно также не может найти соответствие между "h"
и "i",
и ничего между "i"
и "s".
Следующий символ в строке это
пробел. "\b"
находит здесь соответствие потому что пробел это не символ
слова и перед ним есть символ слова. Опять программа
продолжает поиск с "i",
в котором не находит соответствия пробелу.
Продвижение символа и повторный
поиск первой лексеме регулярного выражения, "\b"
находит соответствие пробелу и второй "i"
в строке. Продолжая поиск программа регулярного выражения
найдет что "i"
соответствует "i",
и "s"
соответствует "s".
Сейчас программа попробует найти соответствие второму "\b"
на позиции перед "l".
Это неверно, потому что эта позиция между двумя символами
слова. Программа возвращается к началу регулярного выражения
и продвигается на один символ к "s"
в "island".
Опять "\b"
не находит соответствия и продолжает делать так до тех пор
пока не достигнет второго пробела. Она найдет соответствие
здесь, но неверным будет соответствие "i".
Но "\b"
найдет соответствие позиции перед третьей "i"
в строке. Программа продолжит поиск того что "i"
соответствовать "i",
и "s"
соответствовать "s".
Последняя лексема в регулярном выражении "\b"
также найдет соответствие позиции перед вторым пробелом в
строке потому что пробел не символ слова, и перед ним есть
символ.
Программа успешно найдет
соответствие слову "is"
в нашей строке пропустив два первых символа
i
и
s.Если бы мы использовали регулярное выражение "is",
оно бы нашло соответствие "is"
в слове "This". |
|
Alternation
with The Vertical Bar or Pipe Symbol
I already explained how you can
use
character classes
to match a single character out of several possible
characters. Alternation is similar. You can use
alternation to match a single regular expression out of
several possible regular expressions.
If you want to search for the
literal text "cat"
or "dog",
separate both options with a vertical bar or pipe symbol: "cat|dog".
If you want more options, simply expand the list: "cat|dog|mouse|fish"
.
The alternation operator has the
lowest precedence of all regex operators. That is, it
tells the regex engine to match either everything to the
left of the vertical bar, or everything to the right of the
vertical bar. If you want to limit the reach of the
alternation, you will need to use round brackets for
grouping. If we want to improve the first example to
match whole words only, we would need to use "\b(cat|dog)\b".
This tells the regex engine to find a
word boundary,
then either "cat" or "dog", and then another
word boundary. If we had omitted the round brackets,
the regex engine would have searched for "a word boundary
followed by cat", or, "dog followed by a word boundary.
|
Чередование с
символами вертикальной полосы или канала
Я уже объяснял, как вы можете
использовать символьные виды, чтобы найти соответствие
одному символу из нескольких возможных символов.
Похожим есть и чередование. Вы можете использовать
чередование, чтобы найти соответствие в одном регулярном
выражении из нескольких возможных регулярных выраже6ний.
Если вы хотите найти в тексте
слова "cat"
или "dog",
разделите оба настроечных элемента вертикальной линией или
символом канала: "cat|dog".
Если вы хотите больше иметь больший выбор, просто разверните
список: "cat|dog|mouse|fish".
Оператор чередования имеет самое
низкое преимущество из всех операторов регулярных выражений.
Это означает что сначала программа регулярных выражений
будет искать соответствие операторам или слева, или справа
от вертикальной полосы. Если вы хотите ограничить доступ к
чередованию вам нужно будет использовать вокруг скобки для
группировки. Если мы хотим улучшить первый пример чтобы
найти соответствие только целым словам, нам нужно будет
использовать "\b(cat|dog)\b".
Это указывает программе регулярных выражений найти границу
слова, затем найти слова "cat"
или
"dog", а затем найти другую границу слова. Если мы
опустим круглые скобки, программа регулярного выражения
искала бы "границу слова, за которым следует текст
"cat"" или "текст
"dog" за которым следует граница слова". |
|
Remember That
The Regex Engine Is Eager
I already explained that
the regex engine is eager.
It will stop searching as soon as it finds a valid match.
The consequence is that in certain situations, the order of
the alternatives matters. Suppose you want to use a
regex to match a list of function names in a programming
language:
Get, GetValue, Set or SetValue. The obvious
solution is "Get|GetValue|Set|SetValue".
Let's see how this works out when the string is "SetValue".
The regex engine starts at the
first token in the regex, "G",
and at the first character in the string, "S".
The match fails. However, the regex engine studied the
entire regular expression before starting. So it knows
that this regular expression uses alternation, and that the
entire regex has not failed yet. So it continues with
the second option, being the second "G"
in the regex. The match fails again. The next
token is the first "S"
in the regex. The match succeeds, and the engine
continues with the next character in the string, as well as
the next token in the regex. The next token in the
regex is the "e"
after the "S"
that just successfully matched. "e"
matches "e".
The next token, "t"
matches "t".
At this point, the third option
in the alternation has been successfully matched.
Because the regex engine is eager, it considers the entire
alternation to have been successfully matched as soon as one
of the options has. In this example, there are no
other tokens in the regex outside the alternation, so the
entire regex has successfully matched "Set"
in "SetValue".
Contrary to what we intended,
the regex did not match the entire string. There are
several solutions. One option is to take into account
that the regex engine is eager, and change the order of the
options. If we use "GetValue|Get|SetValue|Set",
"SetValue"
will be attempted before "Set",
and the engine will match the entire string. We could
also combine the four options into two and use the
question mark
to make part of them optional: "Get(Value)?|Set(Value)?".
Because the question mark is greedy, "SetValue"
will be attempted before "Set".
The best option is probably to
express the fact that we only want to match complete words.
We do not want to match Set or SetValue if the string is "SetValueFunction".
So the solution is "\b(Get|GetValue|Set|SetValue)\b"
or "\b(Get(Value)?|Set(Value)?)\b".
Since all options have the same end, we can optimize this
further to "\b(Get|Set)(Value)?\b"
.
|
Помните что программа
регулярных выражений
Я уже объяснил, что программа
регулярных выражений горит желанием. О6на останавливает
поиск как только находит верное соответствие. Последствием
есть то что в определенных ситуациях необходимо искать
альтернативные решения. Предположим вы хотите использовать
регулярное выражение, чтобы найти соответствие списку
наименований функций в языках программирования:
Get, GetValue, Set or SetValue. Очевидное решение это
"Get|GetValue|Set|SetValue".
Давайте посмотрим, как это делается, на примере строки "SetValue".
Программа регулярных выражений
начинает на первой лексеме регулярного выражения - "G",
и с первого символа строки - "S".
Соответствие не найдено. Однако программа регулярных
выражений полностью изучило регулярное выражение до начала
работы. Это означает, что она продолжит работу со вторым
альтернативным элементом, который будет вторым "G"
в регулярном выражении. и Опять программа не находит
соответствия. Следующая лексема - "S",
первая в регулярном выражении. Соответствие
найдено и программа продолжает работу со следующим символом
строки и также со следующей лексемой регулярном выражении.
Следующая лексема в регулярном выражении - "e"
после "S",
которому успешно найдено соответствие. "e"
регулярного выражения будет найдено "e"
в строке. Следующей лексеме "t"
будет найдено соответствие символу "t"
в строке.
На этот момент третьему
элементу в чередовании было
успешно найдено соответствие. Поскольку программа регулярных
выражений горит желанием выдать результат, как только один
из элементов будет найден. В этом примере нет никаких других
лексем в регулярном выражении за пределами чередования, так
что регулярное выражение успешно найдет соответствие "Set"
в строке "SetValue".
Возвращаясь к тому, что мы уже
обсуждали, регулярное выражение не находит соответствия
строке полностью. Есть несколько решений. Один... |
Лучшие автосерферы -
системы активной раскрутки для Вашего сайта или реферальной
ссылки
|
Ножи охотничьи туристические ranger wenger купить складные ножи wenger ranger магазин купи.
У сельского жителя за долги арестовали volvo xc90.
Ford the official homepage of ford.
Ищите где купить компьютер в офис.
взять быстрый кредит в банке

Подробно о заработке на
сайтах

Последние 10 выплат
16.07.12г.
clixsense $
8.00
3-я
14.07.12г.
neobux
$ 10.02
30-я
25.05.12г.
neobux
$ 10.00
29-я
17.04.12г.
incentria $
1.00
4-я
16.04.12г.
neobux
$ 10.03
28-я
23.03.12г.
buxbaz
$ 2.14
1-я
12.03.12г.
neobux
$ 10.15
27-я
11.03.12г.
clicksia $
1.00
6-я
26.02.12г.
clicksia $
1.00
5-я
13.02.12г.
clixsense $
7.55
2-я
Смотреть все выплаты
..........................................................
Автокликер. Мультикликер. Букс
Заработок в Интернете
|
